
(This post was largely translated from our Japanese Webmaster Central Blog.)It seems the world is going mobile, with many people using mobile phones on a daily basis, and a large user base searching on Google’s mobile search page. However, as a webmaster, running a mobile site and tapping into the mobile search audience isn’t easy. Mobile sites not only use a different format from normal desktop site, but the management methods and expertise required are also quite different. This results in a variety of new challenges. As a mobile search engineer, it’s clear to me that while many mobile sites were designed with mobile viewing in mind, they weren’t designed to be search friendly. I’d like to help ensure that your mobile site is also available for users of mobile search.Here are troubleshooting tips to help ensure that your site is properly crawled and indexed:Verify that your mobile site is indexed by GoogleIf your web site doesn’t show up in the results of a Google mobile search even using the ‘site:’ operator, it may be that your site has one or both of the following issues:Googlebot may not be able to find your site
Googlebot, our crawler, must crawl your site before it can be included in our search index. If you just created the site, we may not yet be aware of it. If that’s the case, create a Mobile Sitemap and submit it to Google to inform us to the site’s existence. A Mobile Sitemap can be submitted using Google Webmaster Tools, in the same way as with a standard Sitemap.Googlebot may not be able to access your site
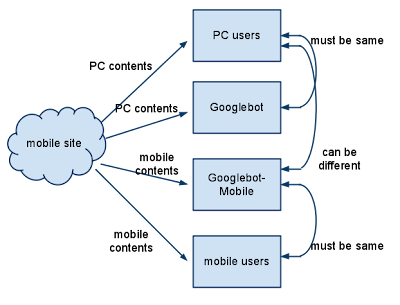
Some mobile sites refuse access to anything but mobile phones, making it impossible for Googlebot to access the site, and therefore making the site unsearchable. Our crawler for mobile sites is “Googlebot-Mobile”. If you’d like your site crawled, please allow any User-agent including “Googlebot-Mobile” to access your site. You should also be aware that Google may change its User-agent information at any time without notice, so it is not recommended that you check if the User-agent exactly matches “Googlebot-Mobile” (which is the string used at present). Instead, check whether the User-agent header contains the string “Googlebot-Mobile”. You can also use DNS Lookups to verify Googlebot.Verify that Google can recognize your mobile URLsOnce Googlebot-Mobile crawls your URLs, we then check for whether the URL is viewable on a mobile device. Pages we determine aren’t viewable on a mobile phone won’t be included in our mobile site index (although they may be included in the regular web index). This determination is based on a variety of factors, one of which is the “DTD (Doc Type Definition)” declaration. Check that your mobile-friendly URLs’ DTD declaration is in an appropriate mobile format such as XHTML Mobile or Compact HTML. If it’s in a compatible format, the page is eligible for the mobile search index. For more information, see the Mobile Webmaster Guidelines.If you have any question regarding mobile site, post your question to our Webmaster Help Forum and webmasters around the world as well as we are happy to help you with your problem.
Help Google index your mobile site
Reference from : by Jun Mukai, Software Engineer, Mobile Search Team










{kind=link}